在全景视频体验中, 听觉沉浸感依赖于高保真的声音再现和音频和视觉线索之间的精确空间对齐. 因此说当前的研究从生成单声道转为立体声的生成, 提出问题, 难以建模声源在环绕声域中的空间方向性.
当前研究遇到的瓶颈, 1) 重建误差与首帧延迟之间的权衡, 基于码本的方式会引入重建损失, 连续的方式会引入首帧延迟; 2) 硬跨模态空间对齐, 大多数的方法依据CLIP编码器, 导致缺乏内在的声学感知能力.
采用的方法就呼之欲出了, AR自回归, 空间声学特征提取模块.
First-Order Ambisionics(FOA)是一种专门用于空间编码的格式, 表示为a∈RC×L, 其中C=4, 代表对应W, X, Y, Z分量的通道数, W携带全向声压, XYZ携带沿正交轴方向的速度分量.
对比学习最典型的就是CLIP, 文本图片对.
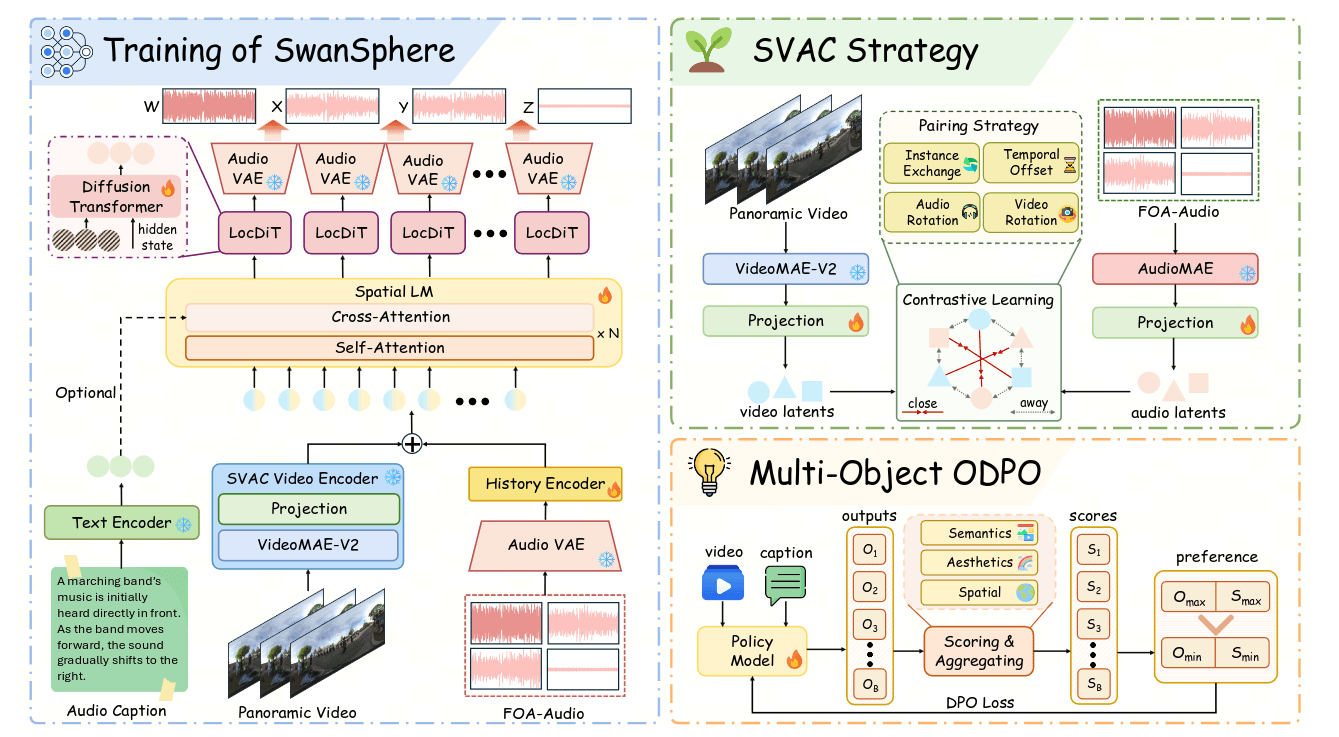
然后他的编码器选择了VideoMAE比CLIP更好的保留全景视频的空间一致性和时间连续性. 因为视频帧率小于音频的帧率, 对视频进行最近邻插帧补齐.
构建了四种正负样本
- 实例交换. 在语义层面上, 匹配的视听片段互为正样本, 而同一个批次内的其他不相关样本则作为负样本.
- 时间偏移. 对同一个视频的音频进行随机的循环移位作为负样本.
- 音频旋转. 针对 FOA 格式音频的空间特性, 模型对原音频进行 3D 旋转改变了声源方向, 并将其作为负样本.
- 视频旋转. 对全景视频进行水平旋转作为负样本, 强制强化视频编码器对全景内容的几何结构及方向一致性的感知能力.
模型使用对称的 InfoNCE 损失函数来进行优化. 目的是将视频和音频的特征映射到一个共享的视听对齐空间中.
这里有一个细节, 通过上面的对比学习, 其实就可以输入视频出音频, 但是类比CLIP, 现在大家不会用CLIP直接出图片对吧, 而是当成一个图片的特征提取器, 从图片中提取语义层次的信息.
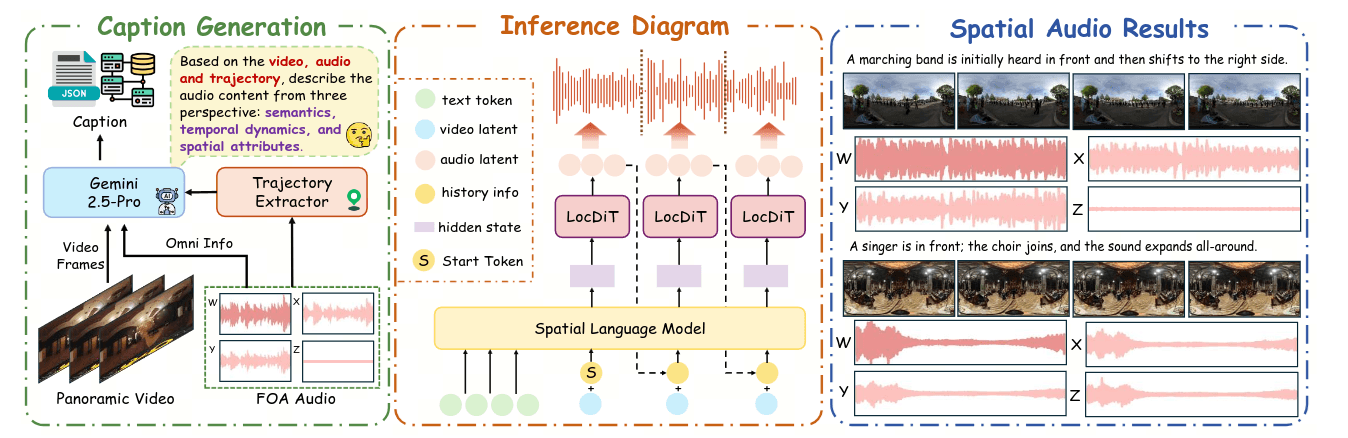
为了真正达到生成的目的, 作者提出了语义规划阶段和生成高保真空间音频的局部生成阶段. 被这两个名词整得很迷糊, 但是从目的看, 语义规划阶段就是编码视频特征的过程, 局部生成就是语言模型在驱动视频和audio上下文下去噪.
他们将非空间音频转换成四通道格式, 以预训练LocDiT.
并行生成8个候选音频样本, 通过综合加权奖励函数进行排序, 奖励函数有声音源定位的物理准确性(生成的空间音频与真实值之间的方位角、仰角和空间角度误差), 语义内容的精确对齐(音频与视频/文本嵌入之间的相似度), 相位失真和机械伪影问题(AudioBox美学来计算生成音频与真实参考音频在感知特征空间中的距离)
为了解决高质量空间音频与对齐全景视频的稀缺问题, 用了非FOA音频, 将其转换为伪 FOA 格式, 全向通道W初始化为原始立体声双通道的叠加和, 随机选择 X, Y, Z 中的一个通道, 存储原始双通道之间的差值, 而将剩余的两个方向通道直接置零.
然后因为MLLM没有音频的空间感知能力, 实际注入的是结构化的空间轨迹 JSON 数据.
指标是声学保真度, 语义一致性, 空间准确度, 主观评价引入了 MOS-SQ(空间音频质量)和 MOS-AF(视听/图文对齐忠实度). 在全景视频到音频和文本到音频两个任务上比较.
感受
跟想的有点不一样, 它是全景视频, 音频格式是FOA天然携带空间信息, 任务是text-to-audio和video-to-audio.
他的数据源有两种, 1) 全景相机拍摄的高质量视频, 携带FOA格式的音频; 2) 互联网爬取的视频, 将音频转换成伪FOA格式, 这部分数据只用于预热, 训练高保真的音频(无空间感知能力).
再说方法, 对比学习, FLow Matching和最后一个ODPO训练.