PaperAgent
Gen-Searcher: Reinforcing Agentic Search for Image Generation
落地点是T2I受到冻结内部知识的限制, 在需要最新信息的实际场景中常常失败, 提出了一个搜索增强的agent, 还有GRPO.
Loading...
落地点是T2I受到冻结内部知识的限制, 在需要最新信息的实际场景中常常失败, 提出了一个搜索增强的agent, 还有GRPO.

大多数模型仍然受到预训练期间获得的固定内部知识的根本限制, 举了一些例子, 像涉及特定地标, 公众人物, 新产品发布, 或其它不断变化的真实世界实体.
先前工作有: RAG(静态数据库方位), 基于提示的workflow(需要深度搜索的复杂任务表现不足, 他认为需要train一下).
提出这样的问题: 我们能否训练一个用于图像生成的搜索代理, 该代理能够主动执行多跳网络搜索和推理, 以收集网络中的知识来进行基于事实的图像生成?
三个点: 1) 首次尝试训练一个多模态深度搜索agent用于图像生成; 2) 数据收集pipeline; 3) 实验验证了有效性
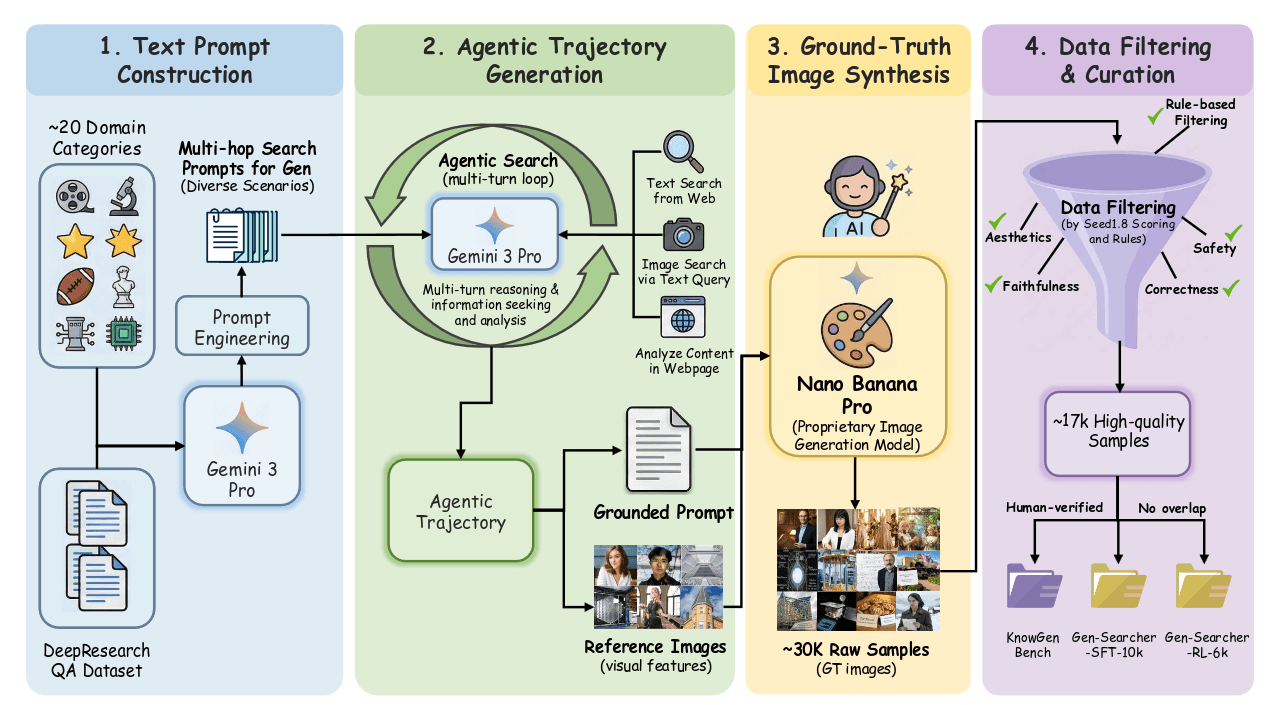
包括四个阶段: 文本提示构建, 代理轨迹生成, 基于实际的图像合成以及数据过滤和整理.
文本提示构建. 提示词工程, 让Gemini 3 Pro去生成包含20个类别的密集型提示, 这些提示被明确设计为无法通过单次搜索获得所需信息, 需要在网络中进行多步骤证据聚合和分析. 还从DeepRearch QA数据集中将寻求信息的问题转化为需要生成所查询实体或事件的基础视觉描绘的提示.
代理轨迹生成. 以多轮方式使用Gemini 3 Pro和一套搜索工具(text搜索, 图片搜索, webpage上下文), 生成推理轨迹.
基于实际图像的合成. 获得最终的视觉参考和基础提示后, 使用我们使用专有的图像生成模型Nano Banana Pro 来合成相应的图像. 产生了30k条数据.
输出过滤和整理. 使用专有模型Seed1.8来评估质量, 留下17k, 从中人工选了630个作为benchmark, 其它用于训练微调.
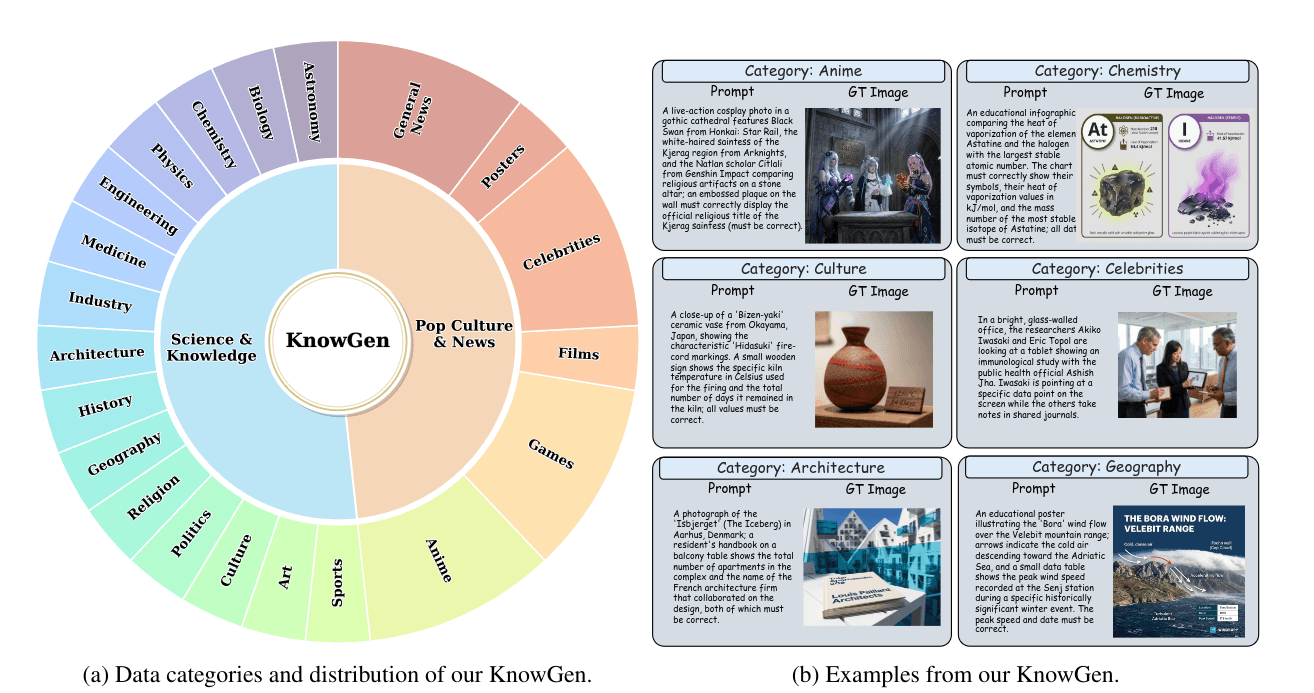
明确关注知识密集型和搜索依赖型生成场景, 需要非平凡的外部知识, 所有评估通过了人工验证. 然后展示了一下他不同的类别, 看图就行.
评估指标. GPT4.1作为裁判, 遵循WISE基准, 从忠实度, 视觉正确性, 文本准确性以及美学对结果进行打分(0, 0.5, 1), K-Score = 0.1 · 忠实度 + 0.4 · 视觉准确性 + 0.4 · 文本准确性 + 0.1 · 美学.
包括SFT和Agentic RL. 一阶段教Qwen3-VL-8B-Instruct工具调用, 二阶段通过RL改善tool call的轨迹.
双重奖励反馈设计. 仅依赖图像奖励会导致大量噪声和不稳定性, 因为最终图像质量不仅取决于检索到的证据的正确性, 还取决于下游图像生成器的能力和随机性. 因此引入了一个额外的基于文本的奖励
使用GRPO来优化策略.
nothing specially.
感受
这算蒸馏了吧, 让gemini生成样本, 再打分选效果好的.
这篇方法应该挺经典的, 先设计pipeline, 让超强闭源模型生成轨迹, 筛选质量高的结果, 再训练开源模型, SFT+RL.