PaperAgent
Mind-Brush: Integrating Agentic Cognitive Search and Reasoning into Image Generation
现有模型本质是静态的文本到像素解码器, 新兴的统一理解-生成模型在意图理解上有所改善, 涉及复杂推理的任务仍然存在困难. 引入 Mind-Brush agent框架, 将生成过程转变为一个动态的, 知识驱动的工作流程
Loading...
现有模型本质是静态的文本到像素解码器, 新兴的统一理解-生成模型在意图理解上有所改善, 涉及复杂推理的任务仍然存在困难. 引入 Mind-Brush agent框架, 将生成过程转变为一个动态的, 知识驱动的工作流程

基本的图像生成模型无法理解人类的深层意图, 统一多模态理解和生成模型在理解用户意图和融合世界知识方面展示了有希望的能力, 但是在需要复杂数学或知识密集型推理的任务中, 其性能仍然受限.
由于预训练模型本身有时间知识截止点的限制, 因此, 它们难以适应现实世界的动态变化, 一些专有模型已经展示了集成搜索能力, 但是开源社区存在差距.
图像生成的agent一个思路是prompt工程, 将简洁的指令扩展为细节丰富的描述, 他们缺乏外部知识.
认知状态(S). 令 表示第 t 步的状态. 它封装了原始用户输入(指令 和可选的参考图像 )以及动态证据缓冲区 , 该缓冲区负责累积检索到的知识和推理链.
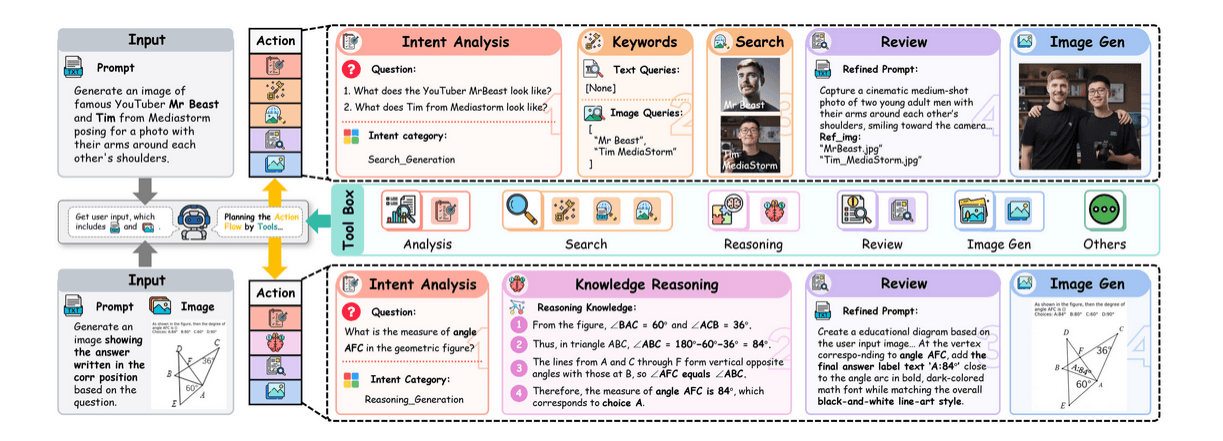
动作空间(A). 智能体可用的操作符集合. 区分了元动作 (认知差距检测, 用于识别认知差距 )和执行动作 后者用于主动获取多模态证据.
执行策略(π). 意图分析模块作为高级策略 运行. 它评估初始状态, 基于识别出的 制定一条确定性的执行路径.
推理过程演变为一条上下文感知的轨迹. 系统并不遵循僵化的工作流, 相反, 它会根据用户的请求进行动态调整. 通过评估初始状态中认知差距的具体性质, 规划器推断出用于积累证据的最佳结构, 将执行路由到专门的搜索或推理分支.
直接看图其实就行, 定义了一些元动作, 意图分析, 需要调用哪些工具, 怎么联级调用, 最后两步一般是review和生成图片, 前面可以是搜图, 可能是推理.
通过5W1H (What, When, Where, Why, Who, and How) 建立一个"Ground Truth"来确定信号主导权.
就External Knowledge Anchoring 和 Internal Logical Derivation, 一个搜索一个推理.
将经过验证的事实和逻辑结论与用户的原始创意意图结合起来, 重新编写成一个结构化的主提示
被设计用于客观评估依赖动态外部知识和用户意图推理的生成任务. 包含500个样本, 10个子场景, 2类任务(知识驱动, 推理驱动), 人工标注, 构建checklist, 评估时只有checklist中的每一项都通过, 这个case才通过(提出CSA指标).
它跟闭源和开源的TI2I比较, Benchmarks是WISE, RISEBench和本文提出的Mind-Bench.
图像生成模型是Qwen-Image-Edit-2512, agent的Backbone MLLM是GPT-5.1, 检索工具调用 Google Search API.
感受
我觉得这玩意openclaw写skill一段prompt就搞定了, 先识别意图, 我是要去外部搜索还是执行内部推理, 如果是外部搜索, 还要对结果进行过滤, 然后有个总结, 生成新的prompt, 可能还携带了外部的image, 调用视频生成模型生成. 最大的工作量是benchmark和写作手法.
投这种paper太看运气了, 看它的三个点: pipeline, benchmark, result. 这种工作放在工程上就好了, 个人认为没有学术探讨的必要.