portrait animation经历了面部关键点 -> 端到端, 以增强视觉保真度和表现力.
引出挑战:
- 向前工作从头训练, 限制了利用丰富的跨模态先验能力. 于是他们build upon BAGEL, Autoregressive Rectified Flow.
- 评估指标是主要瓶颈, 分析了当前指标的问题, 引入基于MLLM的评估框架.
- 统一了建模和评估.
主要依赖低级图像或视频特征中手工制作的特征, 其它常用的度量还包括像素级相似性度量. 它们与人类感知判断的相似性较差.
一种是打分, 一种是比较. 他们对比了qwen3-omni和gemini-2.5-pro, 发现qwen标得基本无效, gemini标得更好.
下面这个总结挺好的:
打分:
- SAS-SA(单方面,单代理):根据人工标注标准,单一多语言大型模型提供一个综合评分,范围在[1, 5]之间。
- MAS-SA(多方面,单代理):单一多语言大型模型为唇形同步、表现力和动作分别预测分数,然后平均形成最终得分。
- MAS-MA(多方面,多代理):每个方面由专门的多语言大型模型评估,并将它们的输出汇总成最终判断。
比较:
- Direct-Comp:使用单一多语言大型模型对两个视频进行整体性的强制选择比较。
- ICL-Comp:通过三个上下文示例增强比较提示——每个评估方面一个——以指导单一多语言大型模型内的更结构化推理。
- MA-Comp(多代理比较):将评估分解到各个方面,其中三个专门的多语言大型模型独立评估唇形同步、表现力和动作,并且第四个多语言大型模型将其决定汇总成最终偏好。
先收集了一个开源数据集, 挑了940个case, 同时让Sonic, Memo, Echomimic输出视频, 这样每个case就有4个视频, 两两配对是6对(他选择了上面比较的方法, 指标就一个"更优"), 标注者3人, 只保留三人结果一致的配对, 最终产生了4501个偏好配对.
他下面要测试的是什么指标与人类偏好更一致, 有传统指标, 大模型指标(比较/打分), 结果是使用gemini 2.5, 基于打分, MAS-MA的准确性最高, 后续使用它.
他们的另一个发现是传统指标测出来的Sonic, Memo, Echomimics三种方法的好坏顺序, 与人类偏好测出来的好坏顺序是不同的, 佐证了传统指标的不足.
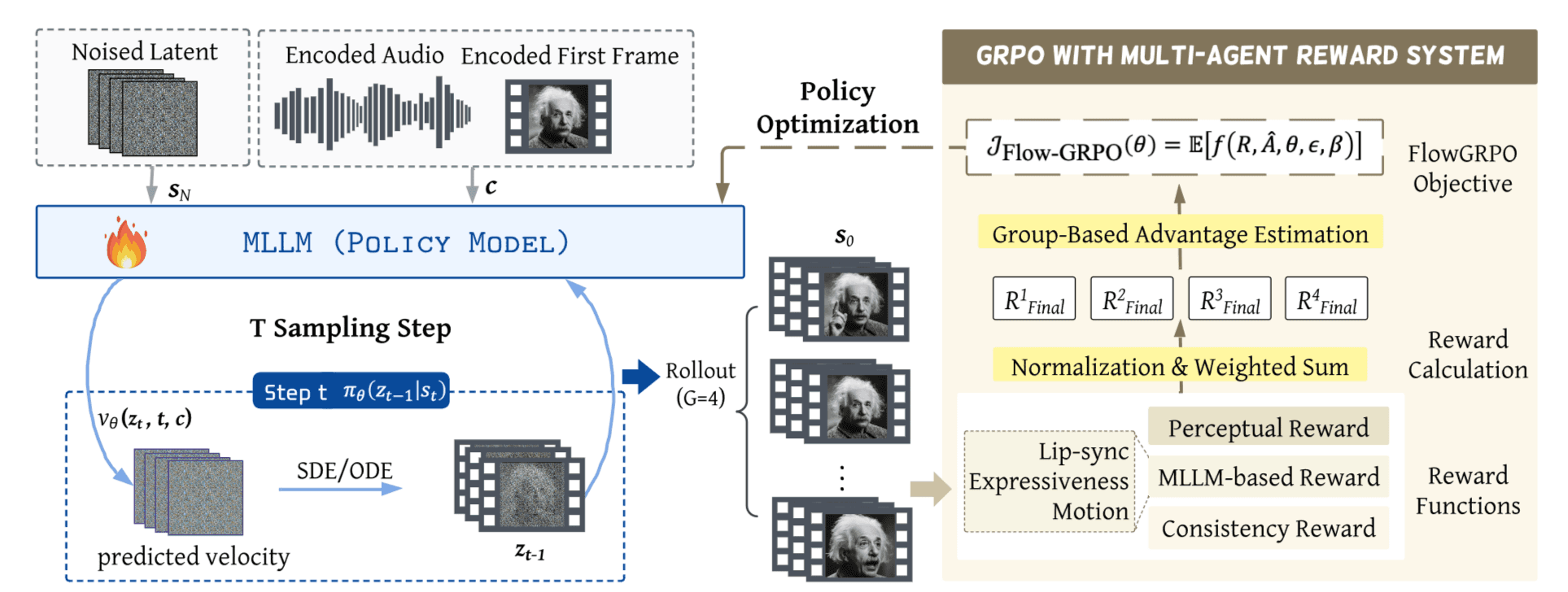
一阶段sft冷启动, 二阶段强化学习. 冷启动设计flow match原理啥的, 就不看了.
这里我自己读的话真的云里雾里, 接住了gemini, 这一节的核心在于
Q: 为什么要用 GRPO?
A: 因为它不需要额外的奖励模型,而是通过同一组采样视频之间的“内部竞争”(组内比较评分)来确定哪些视频生成的更好,从而引导模型进化 。
Q: 如何适配 Flow 模型?
A: 传统的 Flow 生成太死板(确定性),作者通过加入一点“噪声”(随机采样)让模型敢于去尝试不同的生成路径,再通过奖励函数告诉它哪条路是对的 。
只用 MLLM 打分作为奖励会被模型"钻空子", 所以需要设计一个复合奖励来堵住漏洞. (模型发现: 生成抖动/漂移的视频)
GRPO一次生成多个样本, 它需要知道的是每个样本的一个评分, 而不是排名. (对我来说是新知识)
只关心两个维度.
Q. RL训练时怎么设置的超参?
A. 组大小是4, 学习率1e-5(比SFT时小4倍), 采样步数15步(SFT时25步), RL阶段不使用CFG.
Q. 实验部分怎么评估?
A. 1) LLM打分; 2) 人工评估.
感受
人类偏好评分好像在慢慢成为主流, 它们的发现, 传统指标与人类偏好不同, 复合指标大于单一指标. 字节最近发的论文都是人工评估.