Papermotion Customization
AVControl: Efficient Framework for Training Audio-Visual Controls
集合了深度图, pose, 相机轨迹, audio transformations多种控制条件, 不改变模型结构, 平行canvas.
Loading...
集合了深度图, pose, 相机轨迹, audio transformations多种控制条件, 不改变模型结构, 平行canvas.

控制视频和音频模型的生成过程对于实际的创意应用至关重要, 但是可能控制的空间非常庞大, 不同的模式携带不同类型的信息, 相同的输入根据上下文可能具有完全不同的含义.
AVControl的控制范围除了controlnet风格, 还有相机运动, 参考音频. 具体方法后面再看.
它给的三个点有点模糊, 高效, 灵活和训练策略. 估计是用ai写的.
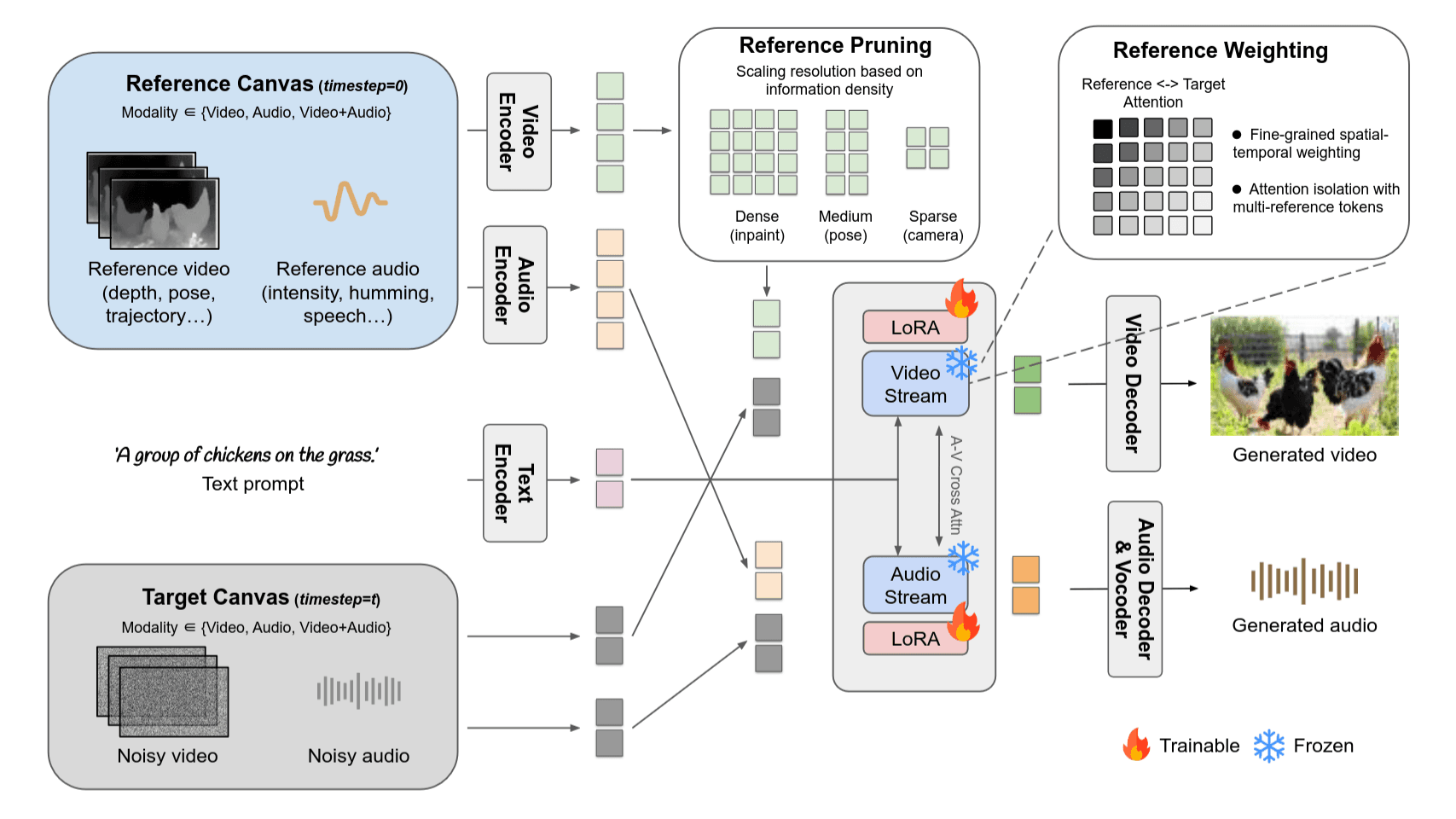
将参考信号纳入扩散模型的一种常见策略是通道拼接, 即将参考信号沿着噪声潜在变量的通道维度进行拼接并输入到扩散模型中. 这几乎不会增加延迟开销, 但需要新的输入投影权重.
参考token沿着序列维度与带有噪声的目标tokens连接, 因为两者的噪声时间步不同, 不需要增加位置编码.
训练时使用LoRA(attention projection matrices and feed-forward layer), 说了三个优点, 在我看来强行与Channel Concatenation对比水字数的: 1)训练高效; 2)细颗粒度reference权重; 3)支持非对齐参考.
Channel Concatenation是Stable Animation用的方法, 在输入前做物理拼接.
可以单独在视频流或音频流上训练, 也可以在双流上训练.
为了组合多个控制信号, 通过合成将它们合并到一个画布上. (有疑问不要问我, 我也没看懂, 论文原文这样说的)
就是method中那个reference pruning图, inpaint用的token最多, pose用得token数与原视频一致, 相机轨迹这种最少.
VACE-benchmark, VBench中抽了六个指标比较.
训练总步数55k, 是VACE的1/3, 生成训练收敛得很快, 查附录发现pose 3k步就收敛了, 刚还在想这怎么做消融, 答案是没做, 就把parallel canvas和Channel Concatenation定性比较了一下.
继承了基模的局限性, 复杂动作与大幅度场景变化处理不佳, 但是更让人在意的是没办法输入参考图条件.
感受
其实整篇论文关键信息极其简单, 在视频信息或音频信息过自注意力之前与外部条件拼接, 保持时间步为0.