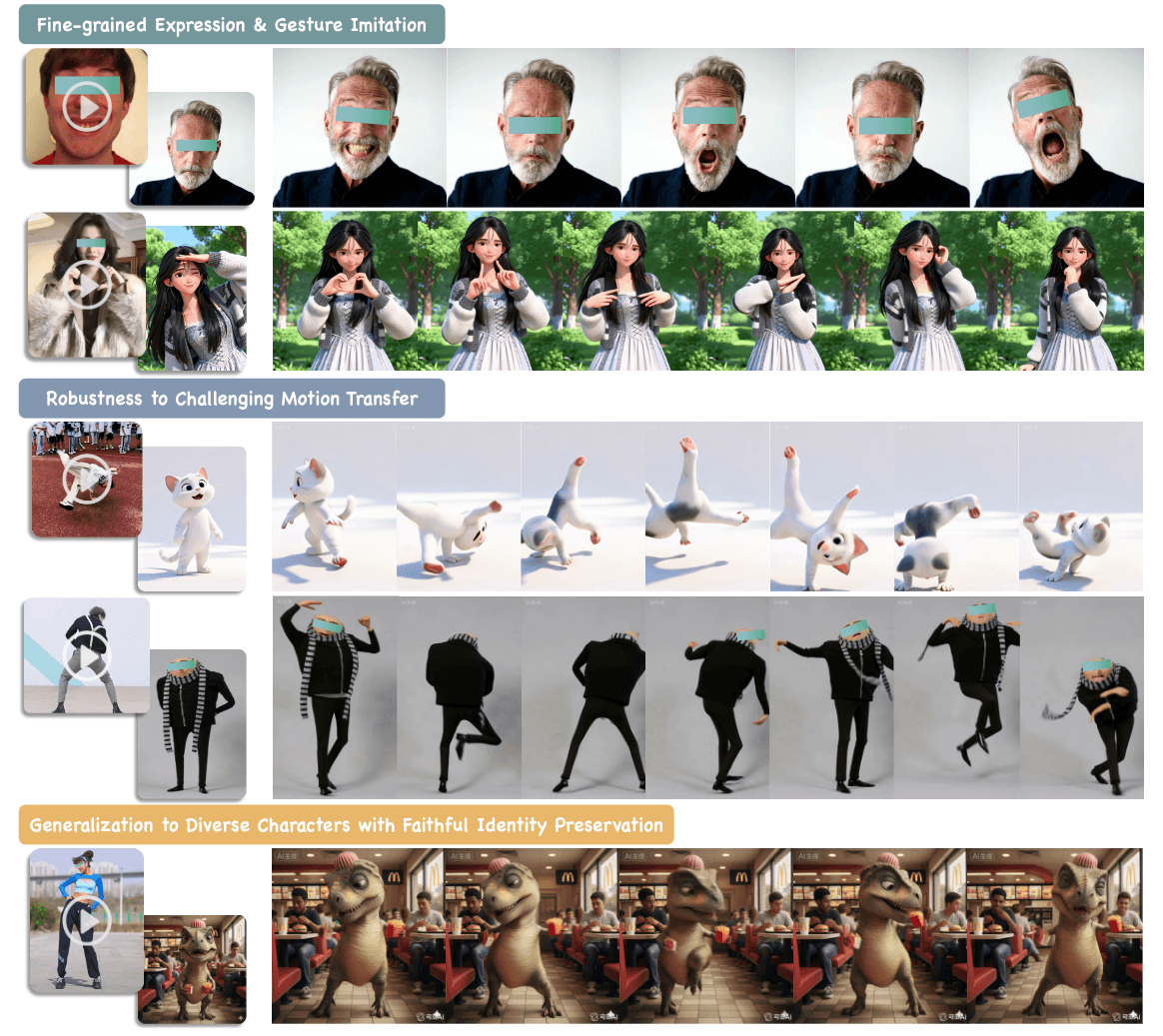
角色图像动画旨在通过将驱动视频中的动态动作转移到包含特定主体的参考图像上来生成动画视频, 应用广泛.
然后讲历史并引出问题, 面部重建or身体控制 -> 全身动画, 指出问题: 难以平衡大颗粒肢体的稳定性和精细细节, 跨身份时身份漂移问题. 另外有限考虑动作约束时, 往往失去对背景, 摄像机移动的控制. 还有推理效率.
方法中包含超多trick, 后面再读. (woc, 没有method了)
统一的多颗粒度动作策划. 像手部, 脸部和身体, 进行多阶段训练. 好朴素的方法, 每阶段应该要用不同类型的训练数据吧? 手部可以用手指舞, 脸部可以用talking head, 全身就用舞蹈视频等等.
自适应的跨身份的动作迁移. 引入了一种与身份无关的动作学习范式, 在几何层面将动态模式与驱动主体的物理属性解耦来提炼动作的本质, 进一步结合了一个语义动作建模模块以捕捉动作的语义层次意图. 即从驱动视频中提取出文本语义和语义语义.
身份保持. "通过细致地提取和整合身份嵌入", 说了等于没说, 但是代替支持输入单张, 它可以输入多张主体的参考图或者视频片段, 全面的上下文使模型能够构建更强大的身份表示.
3D相机视角控制. 多视角监督, 允许用户通过原生文本描述直接控制动态摄像机轨迹.
智能文本响应. 内置了提示词增强模块.
推理加速. 双分支采样使教师模型能够在不增加多个推理分支的计算负担的情况下处理CFG, DMD减少采样步数. (很常见的策略)
数据整理框架. 广泛角色类型和多样化动态动作的大规模数据集, 补充了高质量渲染数据和通过高速摄像机捕捉的镜头, 以支持快速和复杂动作的优化. 标注了视频整体质量分数, 动态动作(例如幅度和平滑度)以及主体一致性等关键指标. 细粒度标注系统涵盖了包括具体动作, 微表情, 人物与物体互动以及摄像机移动等详细属性.
150个高质量测试案例, 完全使用人类评估. 评估维度: 1)视觉质量; 2)动态质量; 3)身份保持; 4)动作准确性; 5)表情准确性.
比较对象有意思, Dreamina和Runway Act-Two两款商业闭源, Wan-Animate开源的SOTA.
我估计这个事情在后面method它还会讲, 但是最近很关注这方面还是留下一段话, "通过利用我们的语义运动引导和提示增强器,Kling-MotionControl保持了忠实的文字响应性, 这一能力允许对超出参考图像之外的属性进行灵活操作——如角色服装, 背景元素和环境变化——从而显著提高整体可控性". 一种divide-and-conquer的思想, 传统pose控制背景肯定是静止的, 通过强化text的权重, 让参考图像外的控制变得可能.
它给的case也是这样的, 驱动视频只控制pose, 但是我可以通过text在视频中添加一只小狗从身边经过.
感受
我觉得pose控制太强了, 属于像素级别的对齐, 早期animate anyone使用的clip那种图片语义级别的信息, 更是强化了这一弱势, 怎么实现pose之外的控制会是未来的一个方向.
这篇论文给我的感受是DiT模型的能力已经到这个阶段了, 不再是像素级别的对齐(一个统一框架解决了之前很多的细分领域任务), 可以做一些更个性化的事情. 虽然它透露的技术细节很少, 但是对于pose控制未来的发展方向很有启发性, 毕竟快手目前在动作控制领域是很强的.
关于每一个具体trick的想法直接写在了正文介绍的相关位置.