PaperWam
World Action Models are Zero-shot Policies
VLA方法对未见的物理动作进行泛化存在困难, 通过共同预测视频和动作, WAMs继承了世界物理的先验知识, 从而实现:1) 从多样化且不重复的数据中有效学习; 2) 开放世界的泛化能力; 3) 仅使用视频数据进行跨实体学习; 4) 对新机器人的少量样本适应.
Loading...
VLA方法对未见的物理动作进行泛化存在困难, 通过共同预测视频和动作, WAMs继承了世界物理的先验知识, 从而实现:1) 从多样化且不重复的数据中有效学习; 2) 开放世界的泛化能力; 3) 仅使用视频数据进行跨实体学习; 4) 对新机器人的少量样本适应.

开头举了一个例子, 说明VLAs往往难以适应新环境或泛化到超出专家演示分布的新任务, 他们基于WAN的14B模型, 以一致方式预测动作和视频的未来状态. 然后说了一下好处, 能够有效地从机器人数据中学习(而不是精心重复的演示), 零样本泛化到心任务, 高效的跨实体转移.
讲优势: 1) 泛化能力, 跨环境, 任务和实体; 2) 从多样异构数据中学习; 3) 少量样本的实体适应.
先指出三大困难: 1) 视频-动作对齐, 简单地结合单独的视频和动作头部可能导致不对齐; 2) 目前尚不清楚双向或自回归架构哪种更适合WAMs; 3) 实时推理.
问题定义是这样的, 其中o是画面, l是当前时间帧, H是未来H帧, a是动作, q是机器臂的状态, c是text条件.
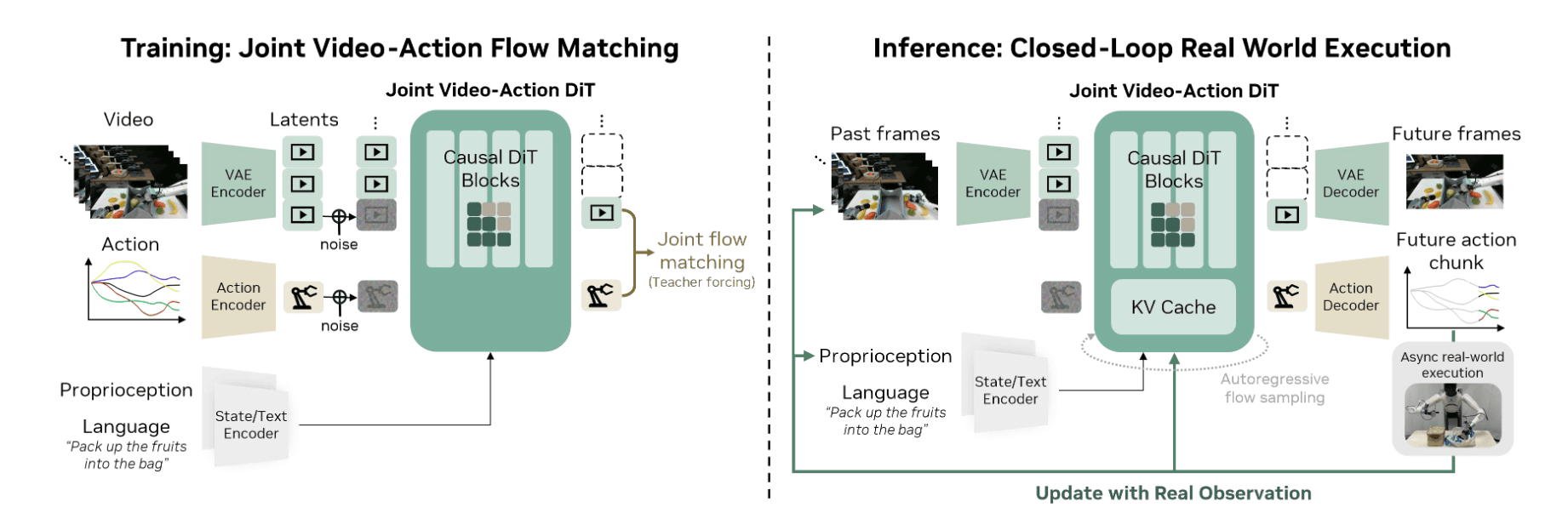
不是使用两个独立的模型来建模分解的目标, 他们训练了一个具有联合预测目标的单一端到端模型.
引入了状态编码器, 动作编码器和解码器. 对于包含多个视角的机器人训练数据, 将所有视角连接成一个单一帧, 而不是对主干模型进行架构更改. 然后训练使用AR方式, teacher forcing.
再往后讲的同步采样步, flow matching训练策略和联合损失函数, 没有花活, 是标准形式, 视频表示和动作表示是直接拼接的.
推理部分讲了KV Caching, 引入真实观测(执行完一个动作后, KV缓存中原本的视频帧被替换成真实视频帧, 这应该是具身独有的优势, 消除了符合误差),
视频生成和动作生成同时进行, 利用两张 GPU 分别并行处理无条件和有条件分支的 CFG 并行化, 通过计算相邻两步速度的余弦相似度来跳过冗余计算的 DiT 缓存机制, 应用 torch.compile 与 CUDA Graphs 消除 CPU 开销, NVFP4 量化, 使用 cuDNN 后端以及将调度器移至 GPU 减少同步停顿.
注意最后一个, 在训练时视频偏向高噪声的 Beta 分布, 动作保持均匀分布, 这个trick在Motubrain中有用过, 不过解释不一样, 训练模型学会在视觉画面仍然模糊嘈杂的情况下预测出精确干净的动作, 从而在推理时直接将去噪步数从 4 步精简到 1 步, 大幅削减延迟.
实验在一款移动双臂机器人和一款单臂机器人上进行, 跨具身实验引入了YAM 机器人(与AgiBot G1 机器人相似但不同, 测试迁移能力的)和人类第一人称视角. 数据集是AgiBot G1(500小时, 涉及家庭超市办公室等22个不同的真实环境, 包含42个子任务), Franka(目前最多样化的开源机器人数据集之一).
评估分未见任务和已见任务, 不过环境和物体始终保持是未见的. 另外还测试了在特定任务数据上进行微调后的表现, 以检查其环境泛化能力是否得以保留.
能更好的从多样化, 非重复的数据中学习; 能泛化到未见任务; 能提升后训练的性能; 能实现强大的跨具身迁移能力; 能实现小样本新具身适应; 低去噪步依旧保持稳定.
认为随着数据量的扩大, 性能提升很promising, 但是在推理速度, 长视距推理, 高精度任务上还有提升的空间, 最后对硬件提供要求, 高自由度和拟合人类形态.
感受
很喜欢它实验结果的结构, 提问然后回答的时候, 我们以后写论文的时候不一定要按照他的这个结构写, 但是可以在写之前进行这个QA的流程, 理顺思路, 我要测什么, 怎么向人证明.