最近具身基础模型的进步主要由VLA策略驱动, 它们主要是在静态图像-文本数据集上进行训练的, 因此经常忽略了对精细世界动态的感知和预测, 导致了行为上的表面模仿而不是对世界物理的时间理解.
视频生成模型兴起, 研究开始探索调整模型进行世界建模, 世界模型旨在预测环境如何响应动作而演变, 这种能力与当基于过去的观察和动作时视频生成模型所做的事情直接一致, 即预测未来的视觉状态.
然后介绍先前的工作, 1) 两步pipeline, 先预测未来画面, 然后一个逆动力学模型从中推断出动作; 2) 同时出视觉和动作.
指出大规模异构多模态数据很重要, 1) 没有动作注释的纯视频数据; 2) 跨不同实体对齐了视频-语言-动作轨迹的机器人数据; 3) 模态确实任务无关的交互数据.
采用UniDiffuser来联合建模和调度视频和动作, 支持五种分布的推理: 视觉-语言-动作策略建模, 世界建模, 视频生成, 逆向动力学, 联合视频-动作预测.
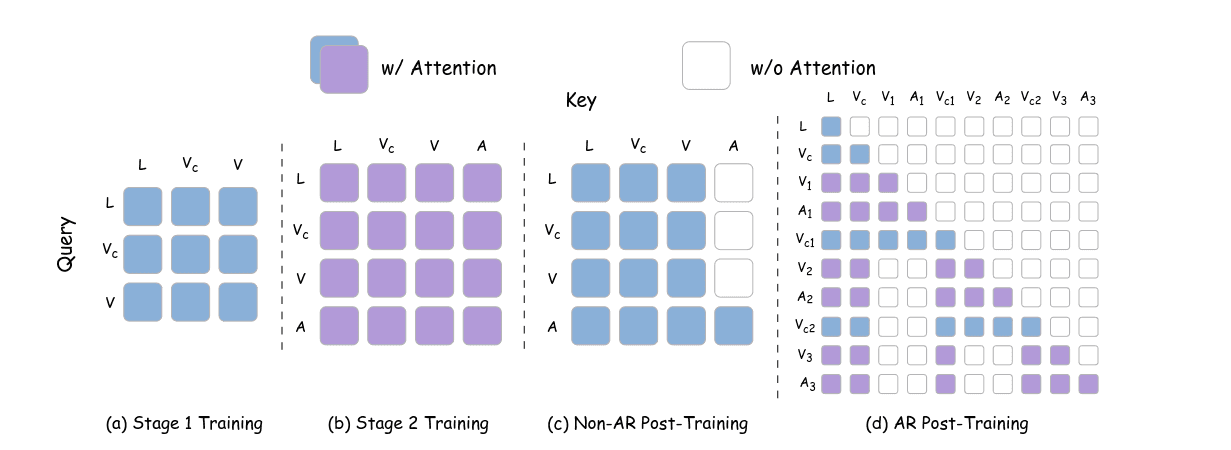
这个UniDiffuser是怎么做的它没细说, 导致这里不太好理解, 后面说了他引入文本流的三流结构保持指令遵循能力, 稀疏的掩码设计保持效率, 还有利用3D RoPE仅沿着空间维度引入视图依赖的偏移量, 同时保持时间维度不变来支持多视图输入.
数据分为四种: 1) 互联网数据, 用来训练基础模型; 2) 以自我为中心的视频, 提供第一人称互动模式和手-物体动态; 3) 异构实体数据, 从不同机器人平台, 任务和场景收集(机械臂); 4) 特定实体数据, 从特定的目标机器人上收集.
一阶段只训练视频分支, 使用以自我为中心的视频和异构数据, 此阶段旨在使互联网规模的视频先验适应实体操作, 并获得能够理解和预测双手交互动态的视频世界模型, 然后讲了一些dropout, 数据增强策略.
第二阶段的异构实体数据上训练动作分支, 冻结视频分支, 所有实体使用统一的动作表示.
关于动作的表示, 这里借助了gemini去理解. 首先明确两个概念, 关节空间和任务空间, 关节空间定义的是根节点的绝对位置, 然后每个节点相对树节点的旋转角. 任务空间不关心树节点旋转角是怎样的, 只关心末端执行器的位置.
因为不同机械臂的关节点不同, 但是任务空间相同, 本文使用任务空间, 具体组成是末端执行器位置(三维), 旋转(6D旋转), 夹爪状态(开合, 一维). 然后就是一些转化了, 位置使用相对位移(相对当前画面), 夹爪的开合状态进行归一化.
专注于将模型适应于目标实体.
论文中的mask图我等会贴出来, Non-AR和AR的方式, 有一个共性, Video是不会主动去看Action的, 这是一个主从关系, Video先生成, Action是忠于Video的. 作者说是为了加速计算, 这种单向依赖允许模型在经历短暂的"视频-动作"联合降噪后, 直接"冻结"视频流的计算, 仅靠缓存的视觉-语言上下文来继续更新动作流(好神奇, 对UniDiffuser越发好奇了, 为什么能这样做)
在AR版本, 块级因果掩码我已经很熟悉了, 切成多个不重叠的块, 只能看过去, 没有干净的动作Token, 然后前面提到的依然是video不看action.
推理加速, 工业关心, 我不关心, 简单过一下吧. 1) 训练时视频的时间偏移是6, 更容易采样到高噪声数据, 因此推理时可以安全的把采样步从50降到30; 2) 计算图加速; 3) FP8量化; 4) DiT Cache; 5) 模型只在最开始的几步联合计算视频和动作, 随后就把计算极其昂贵的视频特征"冻结"并缓存起来, 在剩余的降噪步中, 模型进入"Action-only"模式, 只更新动作 Token; 6) 动作平滑.
当旧动作还没执行完, 模型就生成了新动作块, 直接切换会导致机械臂出现速度跳变, 倒退或高频抖动. 作者设计了一种动作平滑融合策略来解决交接问题: 当发起新的推理请求时, 把当前旧动作块中还没来得及执行的动作提取出来, 作为生成下一个动作的约束条件; 考虑到推理和网络通讯有延迟, 新动作生成期间, 机器人必须继续执行旧动作, 这部分对应的时间窗口被视为"完全受限的冻结区"; 过了冻结区后, 在新旧动作重叠的窗口期, 系统会应用一个指数衰减权重, 让控制权像接力赛一样, 平滑地从上一个动作块过渡到新预测的动作块中; 为了应对现实世界中忽高忽低的网络和推理延迟, 系统维护了一个延迟队列, 保守估计下一次的延迟时间, 并动态调整"冻结区"和"融合窗口"的大小, 保证了异步执行的绝对稳定性.
感受
虽然大家都在说具身左具身右, 但是我读到的很多论文, 提到action, 大家都是指的机械臂, 而不是全身的action, 奇怪. 这个动作是10维的, 相对SMPLX的315维要简单很多.
学习人家在做这直接把action注入时是怎么处理数据的, 位置使用相对位置, 残值而不是绝对值, 旋转用6D旋转角, 只对夹爪的开合状态归一化.
模型架构真正的底层method作者让去看UniDiffuser. 还提到LingBot-VA风格的噪声条件增强, 不知道在训练中是否重要, 作者多次提到了这种技术.
btw, 看到这么实际工程论文, 而不是各种画饼, 才会让人觉得具身可能是一个promising的方向.