PaperWam
UniT: Toward a Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling
将类人基础模型扩展受到机器人数据稀缺性的限制, 尽管大规模以自我为中心的人类数据提供了一种可扩展的替代方案, 但由于运动学不匹配, 弥合跨实体鸿沟仍然是一个基本挑战. 提出了了UniT, 一个建立人类到类人转移统一物理语言的框架
Loading...
将类人基础模型扩展受到机器人数据稀缺性的限制, 尽管大规模以自我为中心的人类数据提供了一种可扩展的替代方案, 但由于运动学不匹配, 弥合跨实体鸿沟仍然是一个基本挑战. 提出了了UniT, 一个建立人类到类人转移统一物理语言的框架
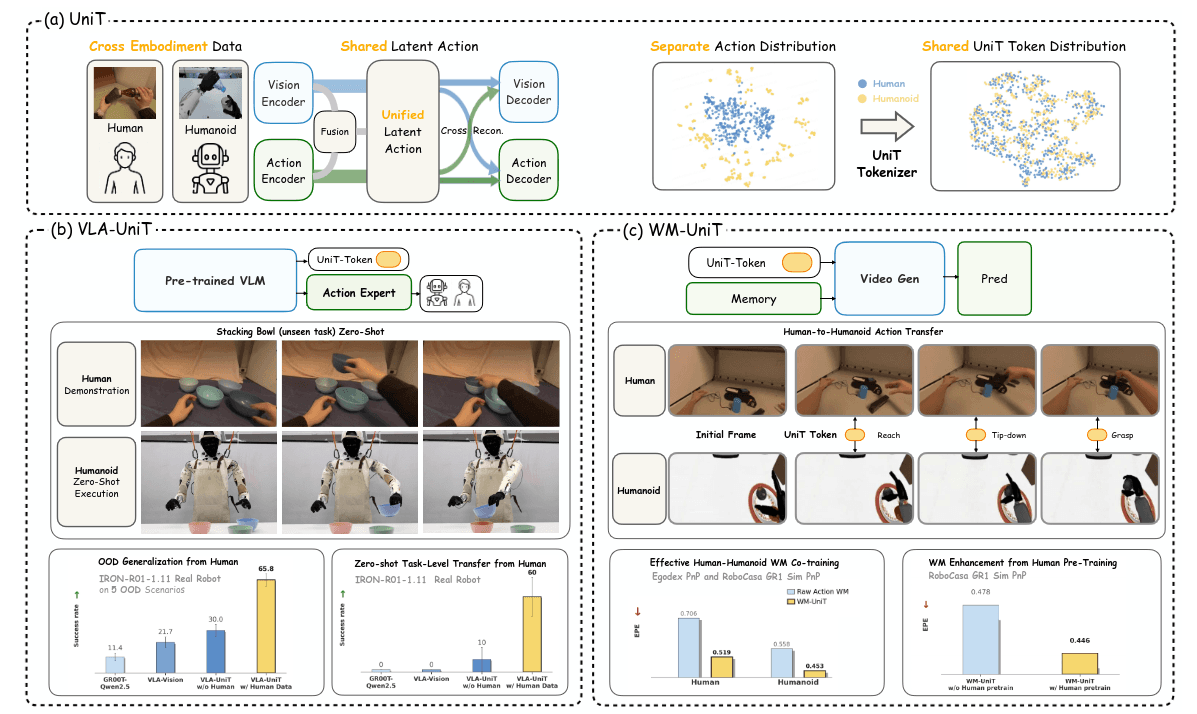
将基础模型扩展到类人机器人在策略学习和世界建模中, 从根本上受到高质量机器人数据稀缺的限制. 大量低成本捕获的结构化人类运动序列提供了一个富含物理交互先验的可扩展替代方案, 但利用它们需要弥合一个主要的跨实体差距. 生物力学和硬件差异导致了自由度和控制范式不匹配的异构状态-动作空间. 传统流程依赖于运动重定向, 使用复杂的运动学求解器将人类运动映射到特定机器人上. 这个逐案处理的过程是劳动密集型的, 不可扩展的, 并且往往在物理上不一致. 因此, 我们需要一种数据驱动的统一物理语言, 将异构数据投影到共享的潜在动作空间中.
先前工作, 仅基于动作的方法完全依赖于本体感觉重建, 由于缺乏外部参考, 经常遭受严重的人类与机器人之间的分布偏移; 新兴的潜在动作框架主要是基于视觉的, 直接从像素推断意图, 虽然绕过了运动学不匹配问题, 但这些表示容易纠缠低级外观混淆因素如纹理和光照, 这种纠缠限制了细粒度的物理执行, 并使人类姿态数据的结构先验未被充分利用. 某些范式同时结合了视觉和动作, 但它们通常为每种模态采用独立的分词器, 这导致词汇表不连贯, 没有深度表示统一, 未能建立真正通用的控制媒介. 另外许多现有的潜在动作系统局限于固定单臂或双臂设置, 配备简单的夹具, 其向灵巧类人机器人的扩展性很大程度上未被探索.
它们的设计基于对跨实体对齐的一个关键见解, 虽然人类和类人机器人的运动学在结构自由度方面有所不同, 并包含实体特有的噪声, 但它们意图的物理结果共享一致的视觉表示. 因此, 视觉观察可以作为普遍的锚点来定位和对齐不同的运动学空间. 基于这一原则, UniT作为一个跨模态信息瓶颈, 提炼出底层的物理意图. 分词器同时提取三个耦合表示: 从连续帧中提取的时间-视觉特征, 从对应帧间动作中提取的运动学特征, 以及融合的视觉-运动特征. 与其将这些视为孤立的数据流, 我们强制执行严格的交叉重构目标, 迫使每个表示能够独立解码视觉转换和低级动作.
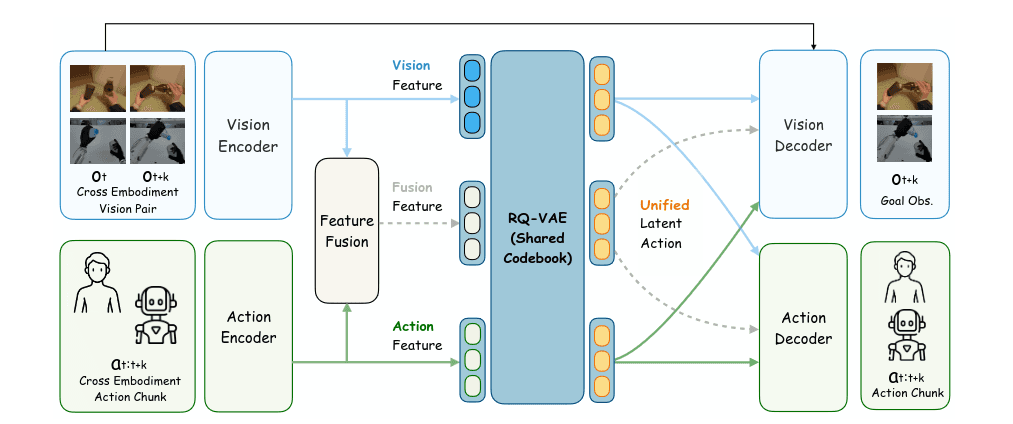
将人类和类人演示视为观察, 特定实体状态和动作的序列().
他训练了一个共享码本. 这个码本的厉害之处在与: 我有两组不同的数据, 一组是人类在操作物体和对应的动作表示, 一组是机器人在操作数据和对应的动作表示, 这个共享码本表示要求, 无论输入源来自人类还是机器人, 无论来自动作分支还是视觉分支, 最终都会被强制落入同一个统一的离散空间中.
为了实现这个目标, 从架构上是一个三分支编码器, 视觉分支, 动作分支, 融合分支(将上述视觉和动作特征进行融合, 捕捉跨模态的互补结构信息)
从训练上, 用于视觉重构的余弦相似度损失, 动作重构损失, 以及 RQ-VAE 自身的量化约束损失.
问题
Q: 我觉得训练损失有点问题吧, 从语义上看, 在视频分支我是希望o经过RQ-VAE编码器后再解码可以还原出视频(视觉), 是这样吗, 但是这个视觉中不是携带了背景光影这些无关信息吗
你指出的正是单纯依赖“视觉-视觉”重构模型(比如早期的 Vision-only 潜在动作模型)最大的痛点——它们非常容易把光照、背景纹理、相机角度等与物理动作无关的“低级外观干扰因素(appearance confounders)”也编码进去 。
如果 UniT 的视觉分支只是单纯地做 的自编码,它绝对会遇到你说的这个问题。但 UniT 的作者在设计时正是为了解决这个问题,在损失函数和架构上做了两个非常巧妙的设计来过滤掉这些无关信息:
1. 终极杀手锏:交叉重构(Cross-Reconstruction)信息瓶颈
这是 UniT 最核心的设计。在 UniT 中,无论 Token 是从视觉分支、动作分支还是融合分支提取出来的,它都必须同时被送入视觉解码器和动作解码器 。
这意味着,视觉分支提取出的 Token (),不仅要能还原视觉特征,还必须能还原出底层的运动学动作(Action) 。
过滤机制的原理:背景光影、桌子颜色、房间布置等视觉信息,与机器人或人的具体关节怎么动(运动学)是毫无关联的(Uncorrelated noise) 。如果视觉 Token 记住了背景光影,这部分信息在通过动作解码器去预测具体的机械臂关节角度时不仅毫无用处,还会增加学习负担。
结果:为了使得总损失(视觉重构损失 + 动作重构损失)最小化,网络会在优化过程中被迫丢弃那些无法映射到动作上的纯视觉背景信息,只保留视觉和动作的交集(本质的物理意图,如“手靠近杯子”) 。
2. 重构目标不是原始像素,而是 DINOv2 语义特征
在公式 (3) 的损失函数中,视觉分支的重构目标并不是还原原始的图像像素(RGB),而是计算与目标图像的 DINOv2 特征的余弦相似度损失 () 。
DINOv2 本身就是一个经过大规模预训练的强大视觉大模型,它提取的特征已经对光照、颜色等低维视觉变化具有很强的鲁棒性,更关注图像的语义和结构 。
因此,解码器不需要去“画”出完美的背景光影,只需要在特征空间中逼近目标状态的语义即可。
介绍了如何将前面学到的统一特征实际应用到机器人的策略学习.
核心任务是: 在给定当前视觉观察 , 当前机器状态 和人类语言指令 的情况下, 预测未来一段连续的动作块 . 它基于 GR00T n1.5 架构, 并采用 Qwen2.5-VL 作为视觉-语言骨干网络.
将策略学习的过程拆解为UniT Token 预测和流匹配动作生成.
(抱歉VLA的论文读得很少, 这里可能没讲清楚)
给定的动作块经过RQ-VAE编码后过一个MLP转成连续的, 通过交叉注意力注入, 其它没啥有用信息.
数据集包含RoboCasa GR1 (虚拟环境), DROID 数据集(人类数据集, 有动作标注), 物理真机实验.
它提出的是一个编码器, 可以用于VLA和WM, 所以baseline更像是消融实验.
实验是以问题为导向:
感受
核心贡献是那个训练的共享码本, 视觉动作统一, 消除了背景光影的影响, 但是背景光影真的可以随意丢掉吗, 在工业上没问题, 在真实世界中就不一定了.
感觉这个训练还挺难的, 就算单单是动作分支, 机器人和人类的动作, 你要统一表示就不简单, 还要融合视觉, 多样性可能不佳?