Papermotion Customization
JoyStreamer: Unlocking Highly Expressive Avatars via Harmonized Text-Audio Conditioning
现存Video Avatar model在与文本指令对齐方面表现出局限性, 特别是在大幅度全身运动, 动态摄像机轨迹, 背景转换或人与物交互时. 我们的方法支持复杂的应用.
Loading...
现存Video Avatar model在与文本指令对齐方面表现出局限性, 特别是在大幅度全身运动, 动态摄像机轨迹, 背景转换或人与物交互时. 我们的方法支持复杂的应用.

哎, 这篇没有pose控制, 是音频驱动的, 想通过text控制人物的动作. 指出以前的方法文本控制质量不佳, 后续一些改进在某一个点上改善, 但是另一个点上效果不佳, 本文希望实现丰富的应用.
分析原因: 1) 数据偏差, 大部分的数据是静止的; 2) 模态间冲突, 同时受到参考图像, 音频, 文本驱动信号的影响, 音频信号控制动态, 参考图片隐含地限制了运动范围, 两种信号引入了相互竞争的归纳偏差.
具体方法后面再看.
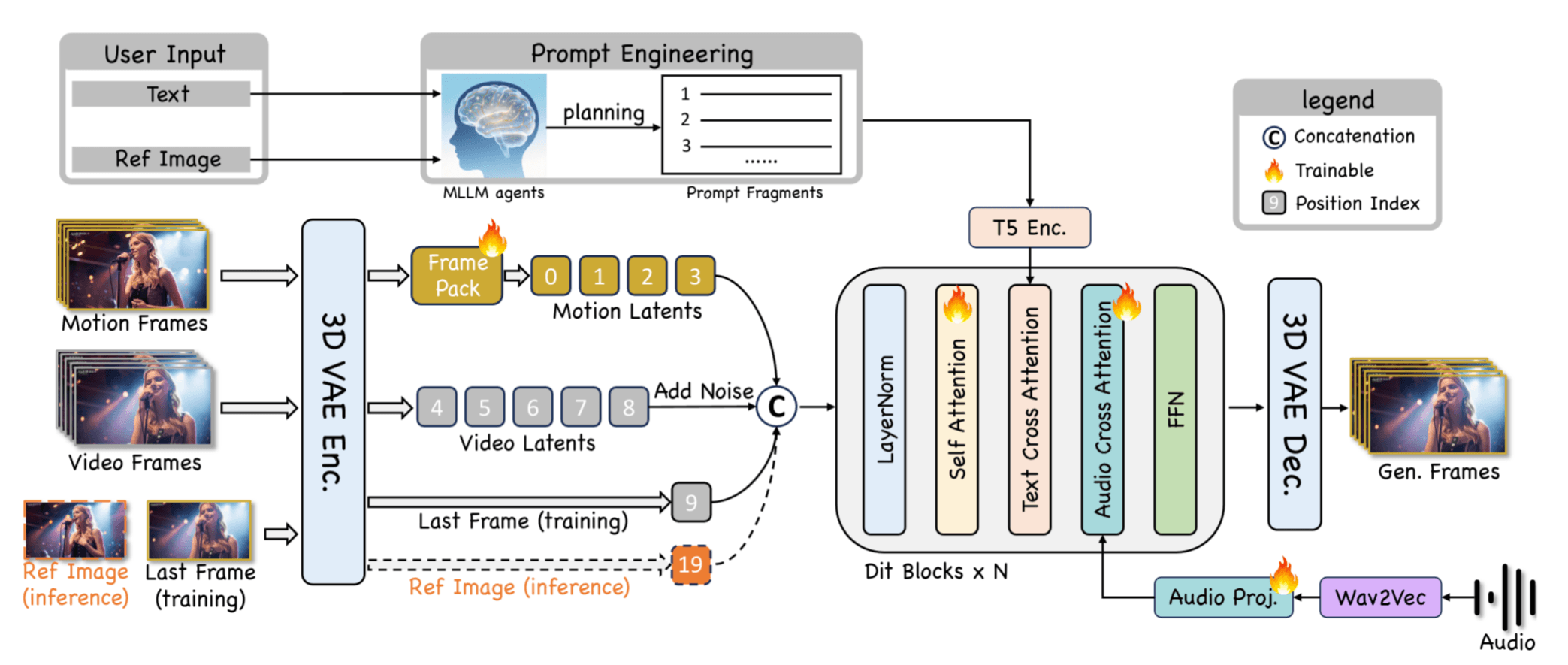
目标是文本遵循, 长视频和唇形同步.
输入的凭借看图很清楚, motion帧(不包含Last Frame)过一个pose特征提取模型FramePack, 视频帧是GT, 参考图用GT的Last Frame.
这里的训练目标有一点反直觉, 它是一个续写任务, 一段长视频可以分成前后两段, 前面一段是motion frames, 后面一段是video frames, 模型的任务是在已知前一段的基础上去补全后半段. 然后这个任务还是分两个阶段, 一阶段是单独训练FramePack和self attention, 第二阶段引入了audio cross attention, 加入了音频条件.
主要是为了提高模型的文本可控性, 同时减少去噪步骤.
Twin-Teacher. 一个音频teacher, 从上一节中训练好的基模, 一个文本teacher, 引入预训练好的强大视频生成模型, 提供高水平的文本监督. 通过重新定义DMD的得分函数, 将两个老师的优势结合.
动态CFG策略. 由于音频信号(控制节奏和口型)与文本信号(控制全局动作)之间往往存在竞争或冲突, 作者设计了一套随去噪时间步变化的调节方案, 高噪声阶段text权重很高, 低噪声阶段audio权重很高. 理论是高噪阶段关注语义, 低噪阶段关注纹理细节.
稳定二次性训练. 作者在实践中发现, 仅通过上述孪生教师训练后的模型虽然动作变强了, 但视频的平滑度和稳定性会有所下降. 因此在完成 post-training 之后, 模型还会进行一轮常规的 DMD 训练, 使用预训练的基础模型作为单一教师, 以找回视觉和时间上的连贯性.
这里是解决有参考图中有多个人, 该让哪个人说话的问题, 方法是通过mask, Queries来自视频的潜变量, 而Keys和Values则源自多个音频流的嵌入向量. 以"人物 1:为例, 只有当视频区域处于"人物 1"的掩码范围内时, 该区域的视频 Token 才会与"音频流 1"进行交叉注意力计算. 对于掩码为 0 的区域(如背景或其他未发言的人), 模型会使用"静音音频"进行交叉注意力计算.
推理时有一个trick, 可以通过控制位置编码偏移来增强动作的丰富度, 参考图的位置索引越大, 动作越丰富. 还有一个提示词工程, 每3.24秒音频用Qwen3-VL生成一个新的prompt, 引导模型在不同时间点做不同的动作.
感受
这个方法很好啊, 把CFG扩展了, 用另一个文本指令遵循很好的模型和对特定任务效果不错, 但是文本遵循不好的模型去共同指导student.
有一点很在意的地方是它的context frames也太长了, 一般这种任务是没有context frame的, 而且这些context frame在推理时也要输入, 限制了应用场景啊.
另一个观察, 最近几篇论文, 数据集都是是工作量最大的地方.