Papermotion Customization
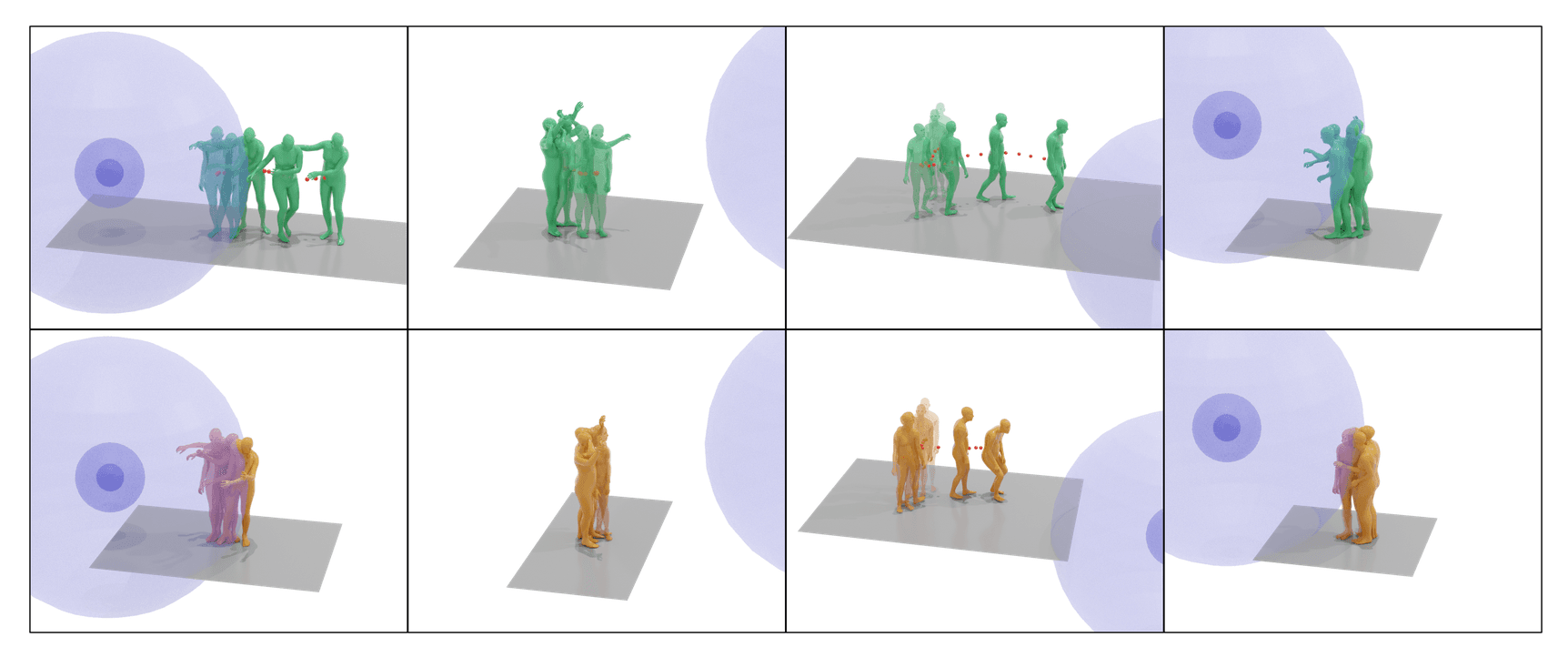
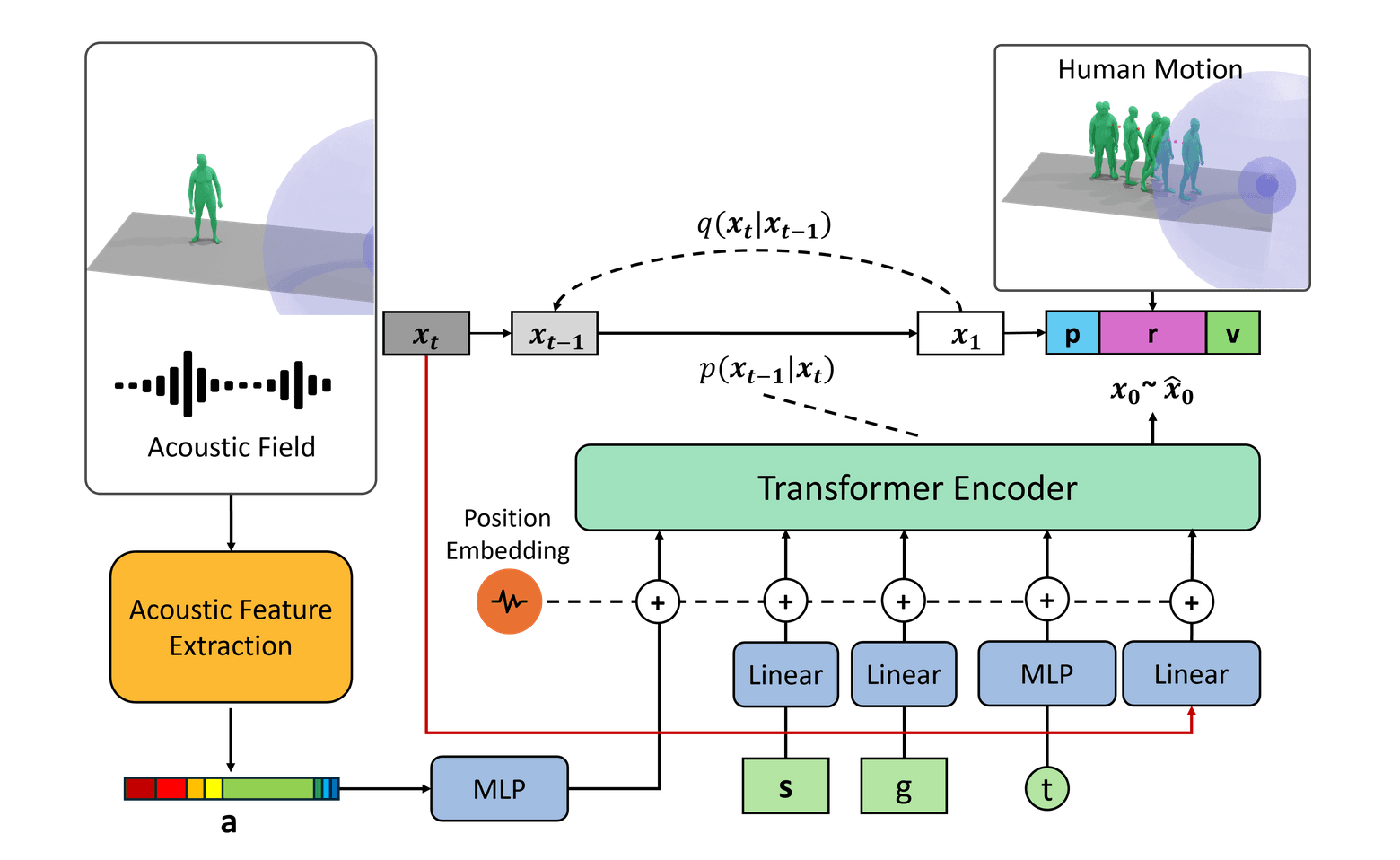
MOSPA: Human Motion Generation Driven by Spatial Audio
空间音频驱动的人体动作生成,提的新任务
Loading...
MagicPose: Realistic Human Poses and Facial Expressions Retargeting with Identity-aware Diffusion
(任务简述我总结了几次, 感觉都没有原文好, 我直接翻译吧): '在这个工作, 我们提出了基于diffusion的模型用于2D人类姿势和面部表情的重构. 给一张参考图, 我们旨在生成一张人类的新的图片, 控制人的姿势或者是面部表达, 保持任务的ip不变'. 讲方法: 使用两阶段训练策略分解人类的动作和外观. 讲效果: 在面部, pose甚至是背景实现稳健的ip控制, 零样本生成, 可作为sd的拓展插件.
OmniForce: On Human-Centered, Large Model Empowered and Cloud-Edge Collaborative AutoML System
autoML旨在用最少的人力投入构建机器学习框架. 先前的工作很少关注在开放世界的良好工作, 一个解决方案是人机交互, 具有机器学习版本管理, 基于流水线的开发与部署, 灵活的搜索策略框架, 广泛提供并众包的应用算法(包括大模型)以及几分钟内提供远程服务这些特点, MaaS(Model as a Service)